前言
没啥灵感,纯属突然想到了。然后瞎折腾,顺便学习
编译二进制文件
这里编译Android终端可以使用的二进制文件需要用到ndk,其工具链提供了相当完整的跨平台交叉编译支持。
这里以Windows下为例,其一般位于AndroidSDK目录\ndk\26.1.10909125\toolchains\llvm\prebuilt\windows-x86_64\bin中
下面编写一个简单的hello world
#include<iostream>
using namespace std;
int main()
{
cout<< "hello world";
return 0;
}使用其中的clang++进行编译(路径均已省略)
.\clang++.exe -target aarch64-linux-android30 -static .\Untitled-1.cpp -o .\helloworldTest上述命令中,参数含义如下
-target 用于指定目标平台,aarch64-linux-android30即安卓平台,api为30的版本
-static 意味着静态连接,对库均进行静态链接,在安卓终端下可以避免一些依赖问题(很显然hello world并没有这种问题)
.\Untitled-1.cpp 为要编译的源代码路径
-o 就是输出文件路径
这里如果代码没有报错,会生成一个名为helloworldTest的二进制文件
这时,使用adb push放进设备,然后chmod赋予执行权限,即可在终端看到hello world的输出。

使用内联汇编
内联汇编即在c/c++环境中使用汇编语言的行为。
内联汇编的语法和编译器有管,不同编译器的内联汇编语法是不一样的。这里以上文使用的clang++为例,其语法和g++是一样的。
下面用内联汇编编写一个最简单的两数相加函数
int add(int a,int b)
{
int result;
asm volatile(
"add %w[a], %w[b], %w[result]"
: [result] "=r" (result)
: [a] "r" (a), [b] "r" (b)
: "memory"
);
return result;
}该函数接收两个参数,并计算其和,放置于result中并返回。在汇编中也是直接使用了add指令实现加法。
其中asm()关键字告诉编译器使用的是内联汇编
volatile则是告诉编译器不要优化这段代码
汇编指令中的%[a], %[b], %[result]则是占位符,会被后面定义的操作数替换
剩下的部分则是扩展内联汇编部分
第一行: [result] "=r" (result)定义了输出操作数(用"=?"(var) 的形式表示)。[result] 是一个符号名,用于替换上面的占位符,"=r" 表示这是一个输出到通用寄存器的值,(result) 是对应的 C 变量。其中r表示使用任意通用寄存器。
除了r之外,还有如下代号用于表示存储方式
m 内存
i 立即数(常量,只用于输入操作数)
g 寄存器、内存、立即数 都行
第二行: [a] "r" (a), [b] "r" (b)定义了输入操作数。[a] 和 [b] 是符号名,用于替换占位符。"r" 表示这些值存储在通用寄存器中,(a) 和 (b) 是对应的 C 变量。
第三行的: "memory"这告诉编译器,内存可能被这段代码修改。这通常用于确保编译器不会做出可能导致错误的优化。
下面写一段完整的代码用于测试
#include<iostream>
using namespace std;
int add(int a,int b)
{
int result;
asm volatile(
"add %w[a], %w[b], %w[result]"
: [result] "=r" (result)
: [a] "r" (a), [b] "r" (b)
: "memory"
);
return result;
}
int main()
{
cout<< add(1,2);
return 0;
}使用上文中相同的操作进行编译运行,即可如下输出,可以看到成功输出了相加结果3。

自修改代码
既然都用到内联汇编了,就要玩一些原生代码不容易做到的骚操作,例如自修改代码(Self-Modified Code)。
自修该代码顾名思义,就是在运行时修改自身代码使其反汇编的内容与实际执行的内容不一致,增加逆向难度。
在不适用内联汇编的情况下,原生代码是不容易实现的,因为原生代码做不到从汇编指令的层面精准控制,无法预估生成指令的长度以及位置,难以修改,且容易产生无法预料的问题。
所以可以通过内联汇编来直接使用汇编指令实现需要被自修该的代码,这样编译生成的代码长度和位置都是固定的,方便对其进行修改。
这次的目的是实现一个在内存中进行自我解密的函数,用于打印hello world。
实现原生代码
这里作为测试,本着加密的代码和外部的关联尽量少的原则,选择直接使用系统调用SYS_write向stdout输出的方式向终端写入内容。
这首先用汇编实现一个使用系统调用输出内容的函数,代码如下
adr x1, 24
mov x0, #1; STDOUT_FILENO
mov x2, #14; len
mov x8, #0x40; SYS_write
svc 0
ret
.ascii "Hello, World!\n"上述代码中,为了直接把需要打印的字符串定义在了函数最后(当然直接在代码段写数据这种行为是不推荐的)。
并且为了减少编译器对地址的干预,没有只用标签和伪指令的方式读取字符串,直接使用了adr根据指令行数跳转到字符串位置,这样可以保证代码的可移植性。
最好是定义在最后,也就是ret后,不然还要防止字符串本身被当成代码执行,需要处理地址跳转的问题
最后套个函数外壳执行即可。
完整的代码如下
void inlinePrintHello()
{
asm volatile(
"adr x1, 24\n\t" // pc向后偏移24,6条指令
"mov x0, #1\n\t"
"mov x2, #14\n\t"
"mov x8, #0x40\n\t"
"svc 0\n\t"
"ret\n\t"
".ascii \"Hello, World!\\n\"\n\t"
:
:
: "memory"
);
}
int main()
{
inlinePrintHello();
return 0;
}编译后可以正常输出hello world

加密指令
这里需要获取上述编译后的二进制数据,对其进行加密。
把上面编译好的内容拖进ida,找到定义好的inlinePrintHello函数
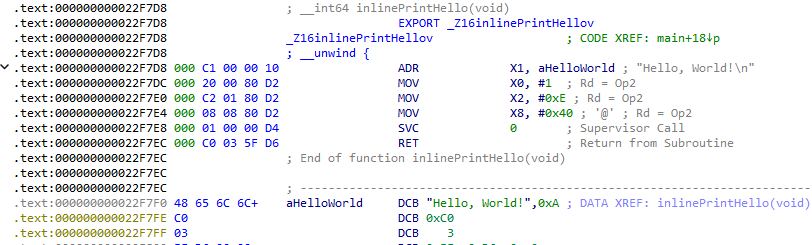
可以看到函数内容没有被丝毫改变,也不包含函数以外的相对地址。
复制复制出函数完整的二进制数据(包含hello world字符串),可以得到
[0xC1, 0x00, 0x00, 0x10, 0x20, 0x00, 0x80, 0xD2, 0xC2, 0x01, 0x80, 0xD2, 0x08, 0x08, 0x80, 0xD2, 0x01, 0x00, 0x00, 0xD4, 0xC0, 0x03, 0x5F, 0xD6, 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x2C, 0x20, 0x57, 0x6F, 0x72, 0x6C, 0x64, 0x21, 0x0A]
这里方便起见只是用简单的抑或进行加密,编写一段简单的python脚本来加密
def encryCode(code,key):
print(".byte",end=" ")
for i in code:
print(hex(i^key),end=",")
print("\b ")
code = [0xC1, 0x00, 0x00, 0x10, 0x20, 0x00, 0x80, 0xD2, 0xC2, 0x01, 0x80, 0xD2, 0x08, 0x08, 0x80, 0xD2, 0x01, 0x00, 0x00, 0xD4, 0xC0, 0x03, 0x5F, 0xD6, 0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x2C, 0x20, 0x57, 0x6F, 0x72, 0x6C, 0x64, 0x21, 0x0A]
encryCode(code,0xff)
这里生成好了加密后的hello world打印函数
完成自修改程序
因为在默认情况下,程序的代码段是只读的,不允许被修改,所以需要先修改其读写权限。
这里使用mprotect函数对内存页权限进行修改。其函数原型如下
#include <sys/mman.h>
//addr: 要修改权限的内存区域的起始地址。这个地址必须是页的起始地址(通常是4KB的倍数)。
//len: 要修改权限的内存区域的长度(以字节为单位)。
//prot: 新的保护标志,可以是以下值的按位或组合:
/*PROT_NONE: 该内存区域不可访问
PROT_READ: 该内存区域可读
PROT_WRITE: 该内存区域可写
PROT_EXEC: 该内存区域可执行*/
int mprotect(void *addr, size_t len, int prot);所以需要先计算出函数所在页的起始地址。
使用sysconf(_SC_PAGESIZE);可以获取当前的页大小,一般为4096
假设上面定义的加密函数地址是code,页大小是pageSize,则当前函数所在页起始地址就是code & ~(pagesize - 1)
pagesize - 1 创建一个掩码,其低位全为1,高位全为0。例如,如果 pagesize 是 4096 (2^12),则 pagesize - 1 是 4095,二进制表示为 0000111111111111.
~(pagesize - 1) 对这个掩码取反,得到一个新的掩码,其低位全为0,高位全为1。继续上面的例子,结果将是 1111000000000000。
所以code & ~(pagesize - 1) 就是将 code 的地址与这个新掩码进行按位与操作,也就是将其地址低位全部置0。这有效的将地址向下舍入到最接近的页面边界。
对于权限,这里直接将其设定为可读写执行,即PROT_READ | PROT_WRITE | PROT_EXEC
所以这里可以编写代码为
long pagesize = sysconf(_SC_PAGESIZE);
mprotect((void *)((unsigned long)code & ~(pagesize - 1)), pagesize, PROT_READ | PROT_WRITE | PROT_EXEC)然后将加密的函数作为数组,对其数值进行抑或
for (int i = 0; i < 38; i++) {
code[i] ^= 0xff;
}由于上述行为修改了代码段中的代码,所以需要执行void __builtin___clear_cache(char *begin, char *end);函数来清除指令缓存。否则可能会因为内存中代码和处理器缓存中代码不一致,导致执行出错。
最后在执行解密完毕的函数后,恢复页权限即可。
完整代码如下
#include <sys/mman.h>
#include <unistd.h>
#include <stdio.h>
void hello()
{
// 加密后的函数
asm volatile(
".byte 0x3e,0xff,0xff,0xef,0xdf,0xff,0x7f,0x2d,0x3d,0xfe,0x7f,0x2d,0xf7,0xf7,0x7f,0x2d,0xfe,0xff,0xff,0x2b,0x3f,0xfc,0xa0,0x29,0xb7,0x9a,0x93,0x93,0x90,0xd3,0xdf,0xa8,0x90,0x8d,0x93,0x9b,0xde,0xf5"
);
}
int main()
{
char *code = (char *)hello;
// 获取页面大小
long pagesize = sysconf(_SC_PAGESIZE);
// 将内存页设置为可写
if (mprotect((void *)((unsigned long)code & ~(pagesize - 1)), pagesize, PROT_READ | PROT_WRITE | PROT_EXEC) != 0) {
perror("mprotect failed");
_exit(1);
}
// 解密代码
for (int i = 0; i < 38; i++) {
code[i] ^= 0xff;
}
// 清除指令缓存,如果不执行可能会导致处理器缓存继续执行解密之前的无效指令,导致异常
__builtin___clear_cache(code, (code + pagesize));
hello();
// 将内存页恢复为只读和可执行
if (mprotect((void *)((unsigned long)code & ~(pagesize - 1)), pagesize, PROT_READ | PROT_EXEC) != 0) {
perror("mprotect failed");
_exit(1);
}
return 0;
}执行代码可以看到,依旧正常输出了hello world。

把其托进ida中进行分析,可以看到hello函数无法被正常识别
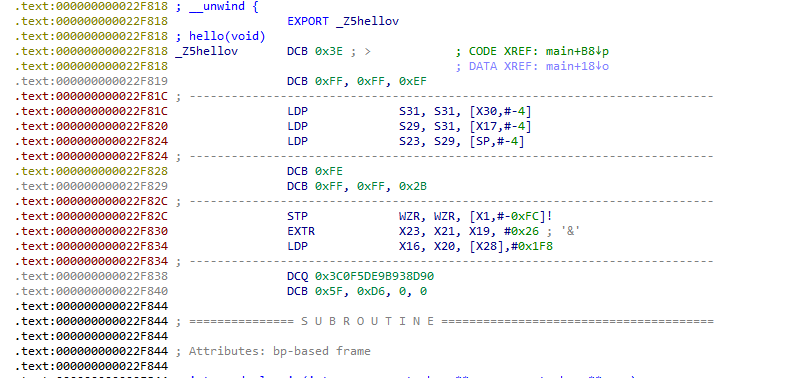
只有在执行的时候,内存中才有函数的正常逻辑

clang ndk中似乎并不支持你说的asm中通过”:”访问C变量的语法
clang是支持GNU 扩展内联汇编语法的,上面的代码测试过可以编译通过,你看下是不是其他地方有问题