一、决策树
1、 基本概念
决策树是一种非参数有监督学习算法
决策树的核心思想是用树状图来表示一组给定数据中的标签或规则,并以此来解决分类和回归问题
根节点:最初提出的问题
中间节点(内部节点):在最终结论得出之前提出的问题
叶子结点:得到的结论
下图为决策树示例
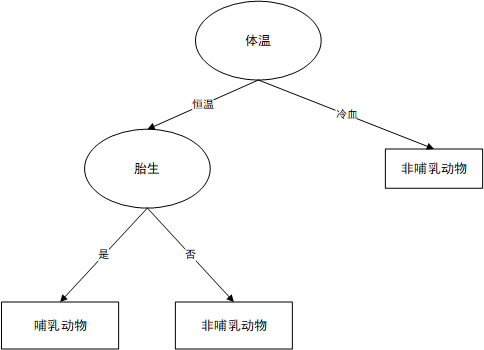
决策树算法的核心是要解决两个问题:
1)如何从数据表中找出最佳节点和最佳分枝?
2)如何让决策树停止生长,防止过拟合?
1.1、sklearn建模流程
- 实例化,建立评估模型对象(实例化)
- 通过模型接口训练模型(训练)
- 通过模型接口提取需要的信息(使用、测试)
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息1.2、sklearn中的决策树
模块:sklearn.tree
| 类 | 作用 |
|---|---|
| tree.DecisionTreeClassifier | 分类树 |
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT格式 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
2、DecisionTreeClassifier(分类树)
2.1、 参数介绍
2.1.1、基本参数
criterion:{“gini”, “entropy”}, default=”gini”
不纯度:衡量决策树节点的指标,该参数默认为基尼系数
树中每一个节点都有不存度,父节点的不存度高于子节点,叶子节点的不存度最低
criterion参数用于决定不纯度计算方式,对于其选择如下
entropy——信息熵,Entropy(t)=-\sum_{i=0}^{c-1}p(i|t)log_{2}p(i|t)
gini——基尼系数,Gini(t)=1-\sum_{i=0}^{c-1}p(i|t)^{2}
当使用信息熵的时候,sklearn实际使用的是父节点与子节点的信息熵差值,即信息增益(Information Gain)
splitter:{“best”, “random”}, default=”best”
用于选择分支节的策略,其选择如下
best——在随机的基础上选择重要程度更高的特征构建分支
random——更加随机的选择节点分支(防止过拟合的方式之一)
random_stateint:int, RandomState instance or None, default=None
用于指定随机状态,其也可以看做随机数种子,类似于random.seed(),所以需要为整数
2.1.2、剪枝参数
剪枝参数主要的作用就是对生成的决策树进行剪枝(减少分支),其主要作用就是为了防止过拟合情况的出现
max_depth:int, default=None
用于限制树的最大深度,将超过最大深度的树枝全部剪掉,对于高纬度低样本量的情况比较有用,建议从3开始尝试
min_samples_split:int or float, default=2
一个节点在分支后的每个子节点都必须包含至少min_samples_split个训练样本,否则分支就不会出现,这可能具有平滑模型的效果,尤其是在回归中。一般建议从5开始尝试。
当该参数为整数时,则将该值作为最小的样本限定数
当该值为浮点数时,则为样本的比例,即将该值*总样本量作为最小样本数的限定
min_samples_leaf:int or float, default=1
用于描述一个结点允许被分支的所需最小样本数,整数与浮点数含义与上面相同
max_features:int, float or {“auto”, “sqrt”, “log2”}, default=None
用于限制分支时所考虑的最大特征数。该参数会直接根据给定值暴力的限制使用额特征,强行使决策树停止
当为整数时,其为最大特征数
当为浮点数时,其最大特征数占总特征数的比例(与上面相似)
当为auto时,最大特征数为\sqrt {总特征数}
当为sqrt时,最大特征数为\sqrt {总特征数}
当为log2时,最大特征数为\log_2总特征数
当为None时,最大特征数为总特征数
min_impurity_decrease:float, default=0.0
用于限制信息熵增益的大小,信息熵增益小于该值则分支不会出现。
可以使用超参数曲线来决定最终的剪枝参数,即以超参数取值为横坐标,模型衡量指标为纵坐标的曲线,可以用于衡量不同超参数下的模型表现
对于超参数较少(一个或两个)的情况,可以使用matplotlib.pyplot库来画出函数图像
对于超参数较多的情况,可以使用sklearn.model_selection库的GridSearchCV函数或RandomizedSearchCV函数进行优化,其分别为网格搜索法和随机参数优化法
超参数为在开始机器学习之前,就人为设置好的参数
前者速度慢于后者但是准确性略高于后者,详细对比见页面
2.1.3、目标权重参数
class_weight:dict, list of dict or “balanced”, default=None
分类权重,用于解决数据集中不同标签结果的数据结果比例不同的问题。
min_weight_fraction_leaf:float, default=0.0