babyre
题目链接:babyre.zip
程序无壳,是一个elf,可以直接分析。
首先执行程序,没有输入提示,但是有input error的输出错误提示。

可以看到程序中有这样一段字符串数据,可以根据这段字符串定位到主要逻辑。

定位到主要逻辑后,可以看到过程相对比较多。在程序的很多地方可以看到和36做对比,所以猜测flag的长度可能为36。其中在这里,在和36做对比,程序指向了两个个不同的分支,一个在下面有大量的流程,另一个则直接输出然后结束了程序。(由于程序流程比较多,所以看不到具体代码)从这里就基本可以确定flag是36位。
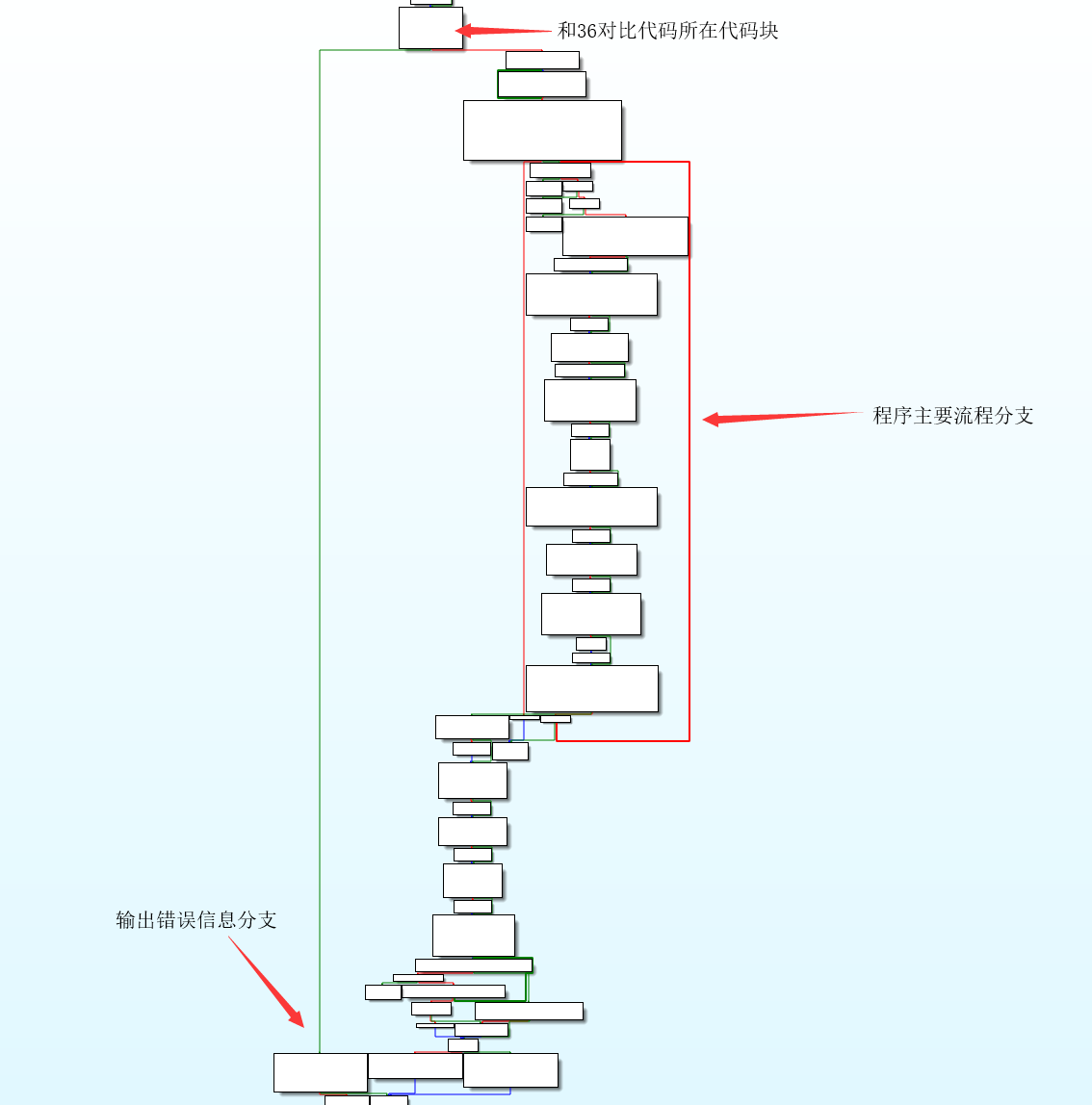
跟踪到右边的流程中,可以看到在程序输出内容之前还有一段过程,其主要是存储了一个固定数据,然后进行了很多次的异或操作。这里可以注意到与固定数据异或的部分是一个地址,其指向的就是这段逻辑的开始地址。
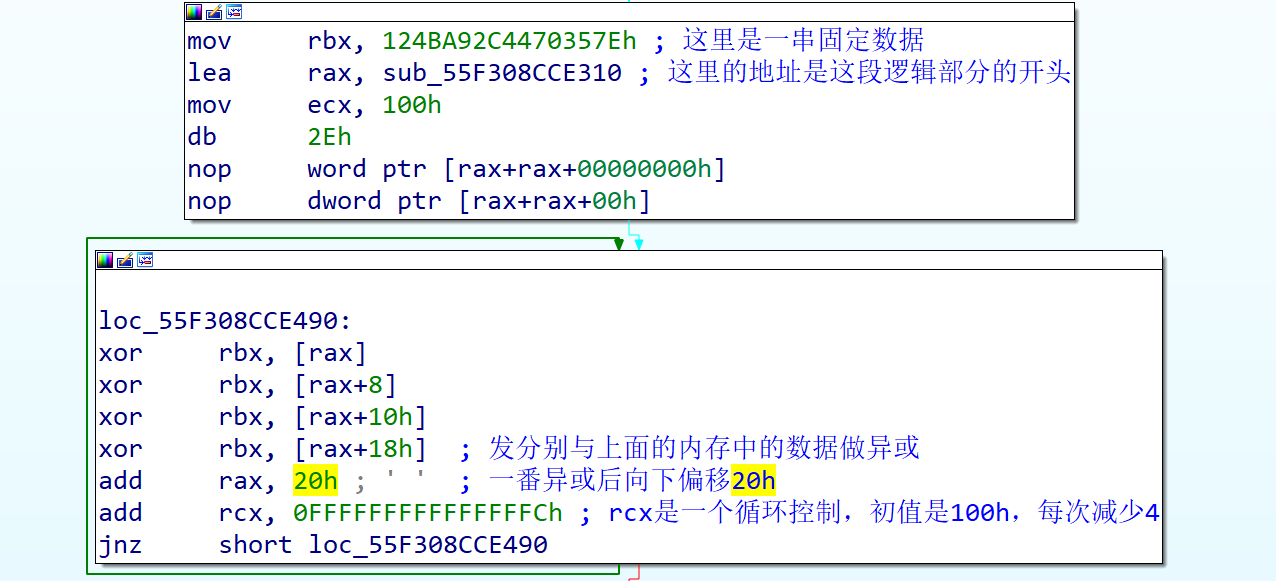
下面的异或是一个循环结构,其循控制变量是100h,每次循环减少4,用固定数据分别和这段逻辑的内存异或,每个循环异或四次,异或后地址偏移20h。所以这段过程其实是计算了这段逻辑的校验和,并且把结果存储在bx中。这个bx在下面会起到很重要的作用。
先看下面,可以找到第一次出现了输入字符串的位置,并且把输入字符串的固定几位放进了寄存器中,过程如图
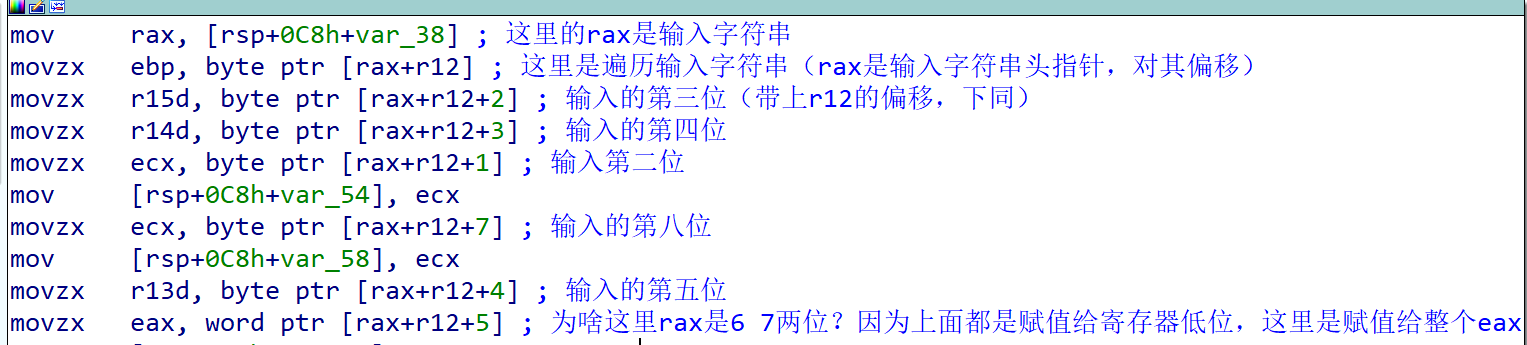
完成了数据的初始化操作,然后是分别对这些数据的处理过程,首先处理的是r15中的数据,从代码中可以看出其把r15和ebp中的数据组合了起来,其就是第一位和第三位,然后和内存中的一串固定数据做异或,再和bx做异或(这里的bx就是上面得到的校验和)。然后将计算后的结果保存在内存中。过程如下图
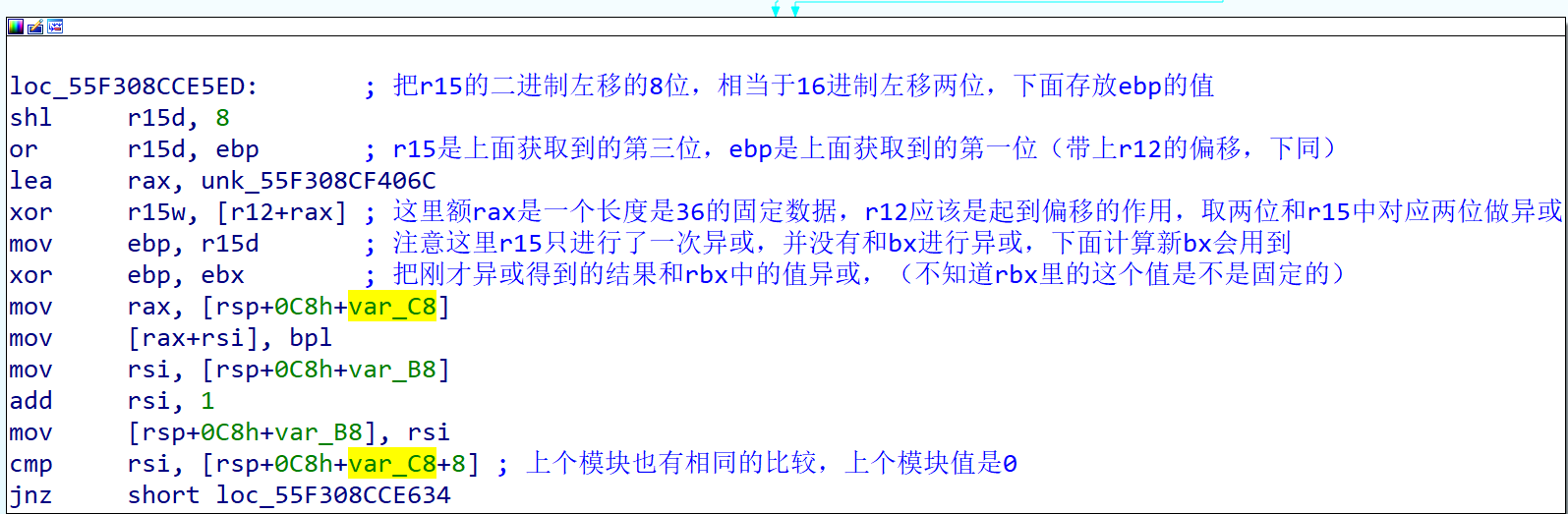
不过这里保存在内存中的是低位(bpl),下面还有一段过程把ebp的高位也放进了内存中。可以看到ebp右移8位,就剩下了上面放进内存剩下的内容,然后接着放进内存。所以其实就是把异或运算后的寄存器内容的第八位和高八位分别放进内存中。
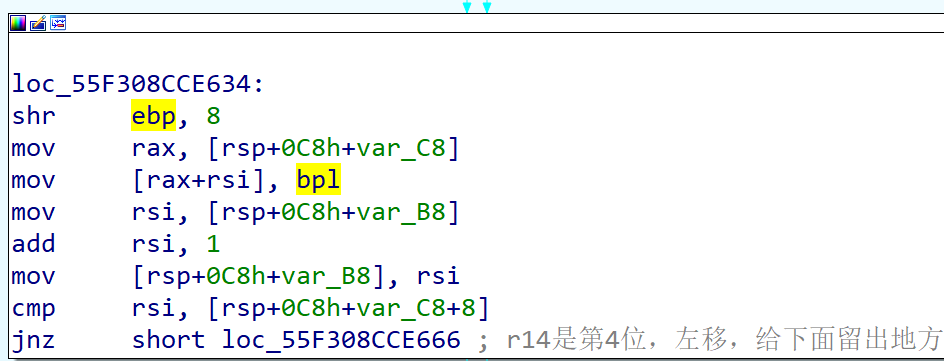
再往下跟踪过程,其过程和上面是类似的,操作了r14和var54中的数据,拼接后首先与bx做异或,然后与固定数据做异或,然后存储数据,与上面过程类似,存储数据的过程相同
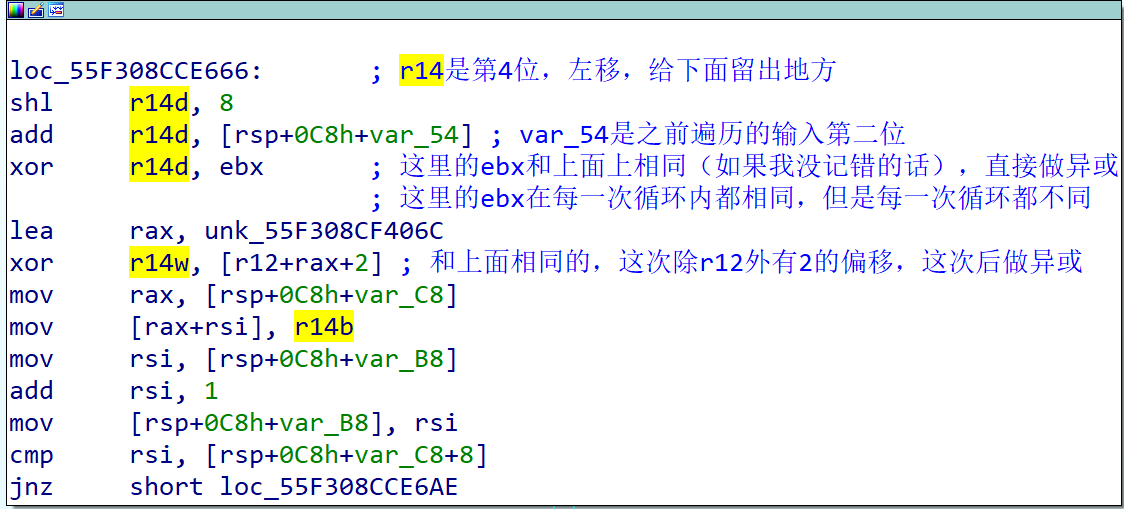
下面也是相似的操作,只是处理的寄存器不同。
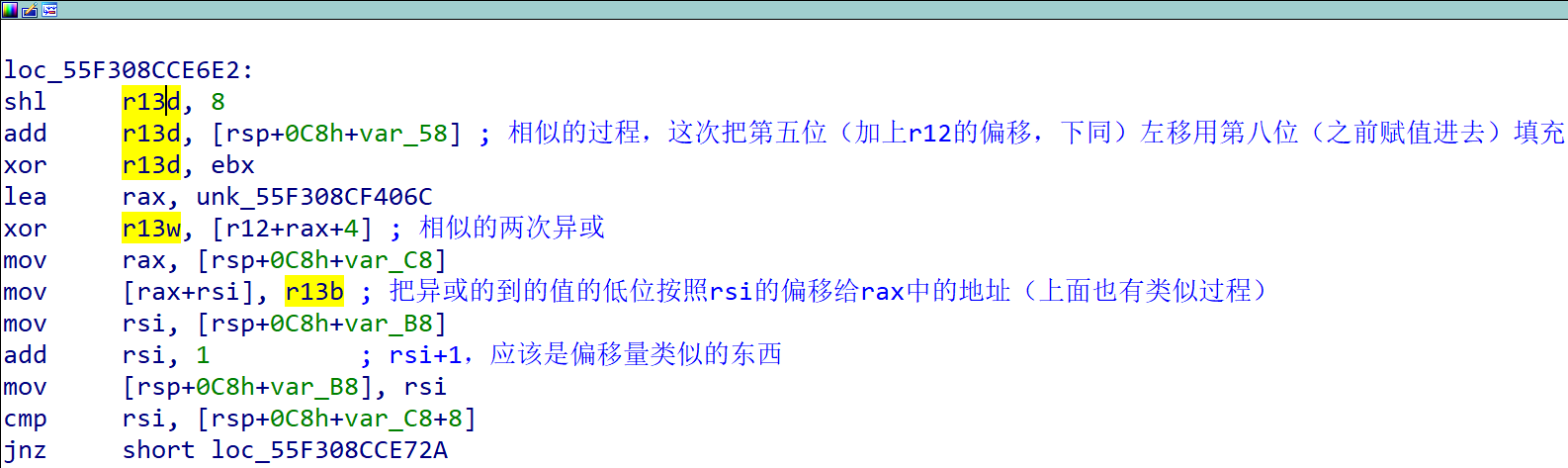
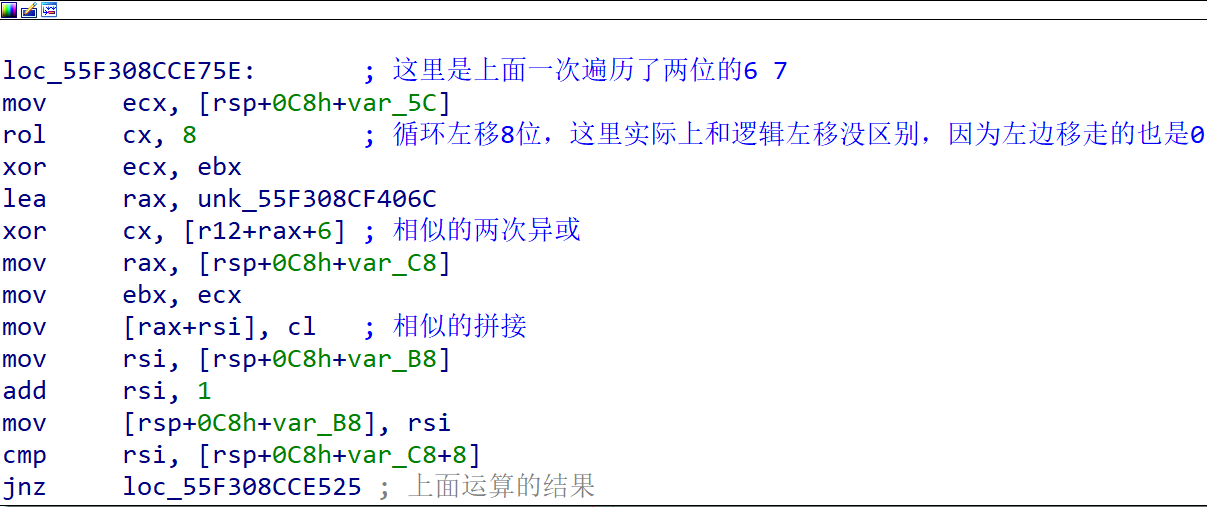
只不过最后一次拼接的过程中间还进行了几次异或,其主要是对上面四次的运算与bx进行了运算得到新的bx,新的bx将循环进入下一次的运算中。其异或过程如下图(我写的太乱了。。。)


然后r12作为循环控制变量,这个过程处理了输入字符串的前32位。

所以上面提到的在这个循环过程之前计算的到的bx就很重要,作为一个初始的bx参与运算,初始的bx值是这段主要逻辑的校验和,所以在调试过程中,如果在主要逻辑中加了断点,校验和就会发生改变(这和调试器断点的原理有关),就会影响最终程序的结果。
在软件反汇编调试程序的过程中需要添加断点,以便让程序停住,其原理就是把断点地址的第一个字节内容改成CC,即int3,触发int3
中断,程序就会暂停在断点处,继续执行的之后再恢复成原来的指令。
这个修改并不会体现在反汇编出来的汇编代码上,在用户直观感受上指令是没有变化的。
不过这只是软件断点的原理,内存断点和硬件断点的原理并不是这样的,其需要使用到drx(dr0-dr7)寄存器,即调试寄存器,这需要cpu的硬件支持。
对于Dr0-Dr3的四个调试寄存器,他们的作用是存放中断的地址,例如:401000,对于Dr4,Dr5这两个寄存器我们一般不使用他们,保留,对于Dr6,Dr7这两个寄存器的作用是用来记录你在Dr0-Dr3中下断的地址的属性
对于后四位的处理,也是相似的过程,对最后四位进行了初始化

下面也有相似的两次异或,只不过这里的两次运算异或的值并不是上面用到的数据(bx是相同的),与上面运算结果的拼接过程也是类似的

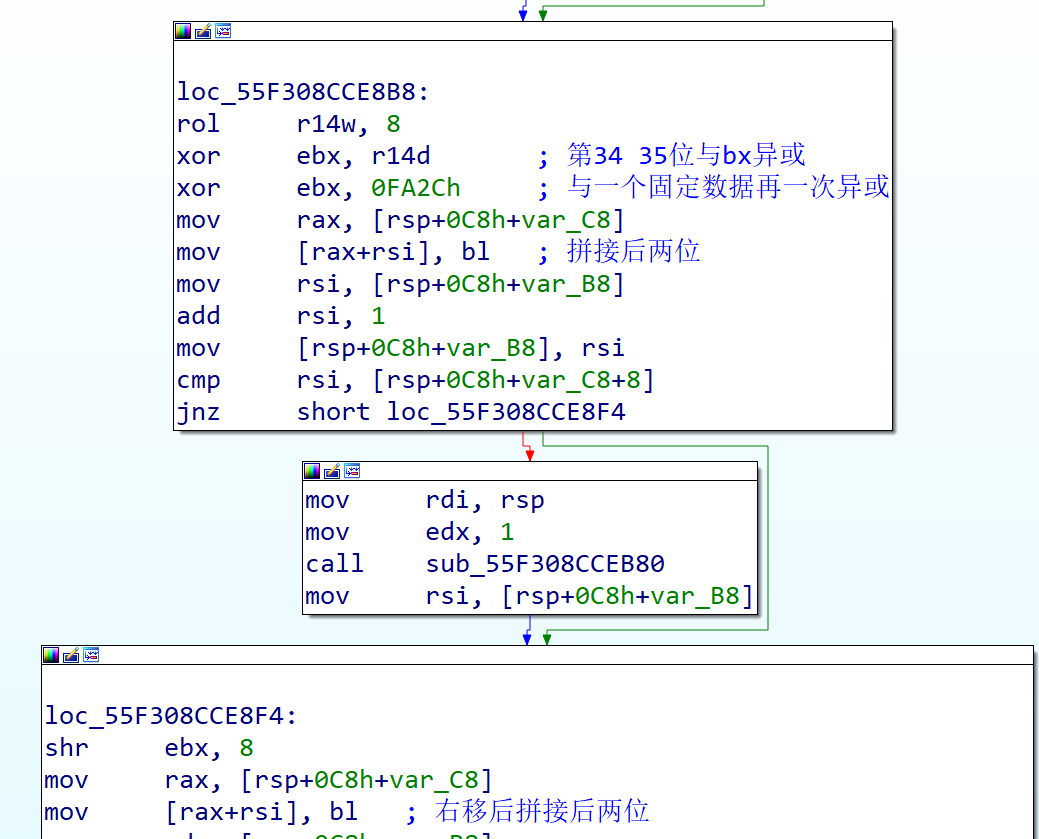
在整个输入的字符串都处理完成后,可以看到紧接着使用了一个36位长的数组,很可能是正确的flag运算后的数据。

其比较过程是一个循环,可以看到输入运算后的输入字符串与上面发现的36位数组按位比较,比较结果有两个分支,一个分支bx为0,一个分支的bx为1
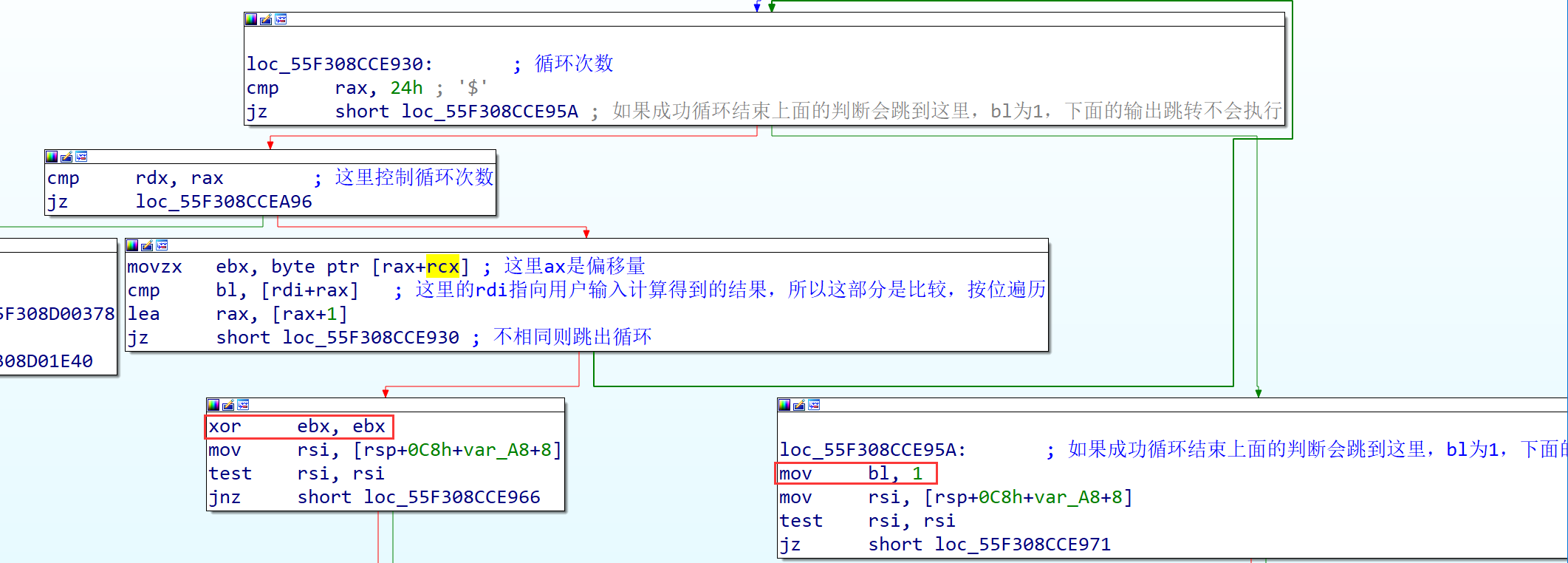
在最后,bx值影响了最后的输出,输出正确过错误的提示,程序结束。
到这里整个程序就分析完了,程序逻辑相对比较复杂,画出一个数据处理的流程图会方便理解很多。
明白了程序的执行过程后,就可以逆出算法得到正确的flag了。
这里是使用idc脚本编写的破解算法,模仿了程序的过程,直接引用了程序的内存,分成8位一组进行运算执行四次,以整型数据的形式保存结果。
static main(void)
{
auto begin,time,i,init;
init=0x124BA92C4470357E;
begin=0x000055F308CCE310;
time=0x100;
do{
init=init^qword(begin);
init=init^qword(begin+0x8);
init=init^qword(begin+0x10);
init=init^qword(begin+0x18);
begin=begin+0x20;
time=time-0x4;
}
while(time>0);
auto l,r,ll,rl,bx;
r=init%0x100000000;
l=(init-r)/0x100000000;
ll=l/0x10000;
rl=r/0x10000;
l=l^ll;
r=r^rl;
bx=l^r;
//print(bx);
auto flag,code;
flag=0x000055F308CF4048;
code=0x000055F308CF406C;
auto flag1,flag11,flag2,flag22,flag3,flag33,flag4,flag44,sum=0x0,j=0;
while(j<4)
{
//print(bx);
flag1=word(flag+j*0x8);
flag1=(flag1^bx^word(code+j*0x8))%0x10000;
flag11=flag1^word(code+j*0x8);
flag1=flag1%0x100*0x100000000000000+flag1/0x100*0x10000000000;
flag2=word(flag+0x2+j*0x8);
flag2=(flag2^bx^word(code+0x2+j*0x8))%0x10000;
flag22=flag2^bx^word(code+0x2+j*0x8);
flag2=flag2%0x100*0x1000000000000+flag2/0x100*0x100000000;
flag3=word(flag+0x4+j*0x8);
flag3=(flag3^bx^word(code+0x4+j*0x8))%0x10000;
flag33=flag3^bx^word(code+0x4+j*0x8);
flag3=flag3%0x100+flag3/0x100*0x1000000;
flag4=word(flag+0x6+j*0x8);
flag4=(flag4^bx^word(code+0x6+j*0x8))%0x10000;
flag44=flag4^bx^word(code+0x6+j*0x8);
flag4=flag4%0x100*0x100+flag4/0x100*0x10000;
print(flag1+flag2+flag3+flag4);
sum=sum+0x10000000000000000*(flag1+flag2+flag3+flag4);
bx=((flag11^flag22)^(flag33^flag44));
j++;
}
auto flag5,flag6,flag7,flag8,bp;
flag5=word(flag+32);
flag7=word(flag+34);
flag5=(flag5^bx^0xFFFFBF9E)%0x10000;
flag5=flag5%0x100*0x1000000+flag5/0x100;
flag7=(flag7^bx^0xFA2C)%0x10000;
flag7=flag7%0x100*0x100+flag7/0x100*0x10000;
print(flag5+flag7);
}运行脚本后即可得到正确的flag(flag顺序与左边16进制的顺序相同,右边字符串形式的顺序相反)
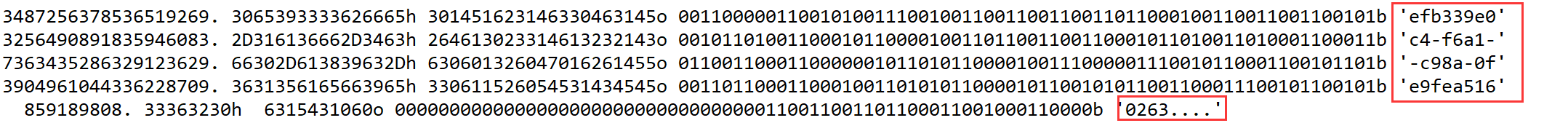
以后还是要学一下IDApython,直接用python编写要比idc脚本更灵活一点。